wanqq@DESKTOP-QL4SAK6:/mnt/d/study/nginx/logs/parsing-record$ cat access.log | awk -F" +" 'BEGIN{print "状态码 IP 请求类型 请求url"} NR < 20 && ($9~/[^23][0-9]{2}/) {print $9,$1,$6,$7}' | sed 's#"##' | column -t 状态码 IP 请求类型 请求url 500 172.17.0.1 GET / 500 172.17.0.1 GET / 500 172.17.0.1 GET / 500 172.17.0.1 GET / 404 172.17.0.1 GET /pushParsingXMLTask 404 172.17.0.1 GET /pushParsingXMLTask 404 172.17.0.1 GET /pushParsingXMLTask 500 172.17.0.1 GET /index/loadFiles/path/app()-%3EgetRootPath().%22public/static/recordXML/%22 404 172.17.0.1 GET /index/loadFiles/path/app()-%3EgetRootPath().%22public/static/recordXML/%22
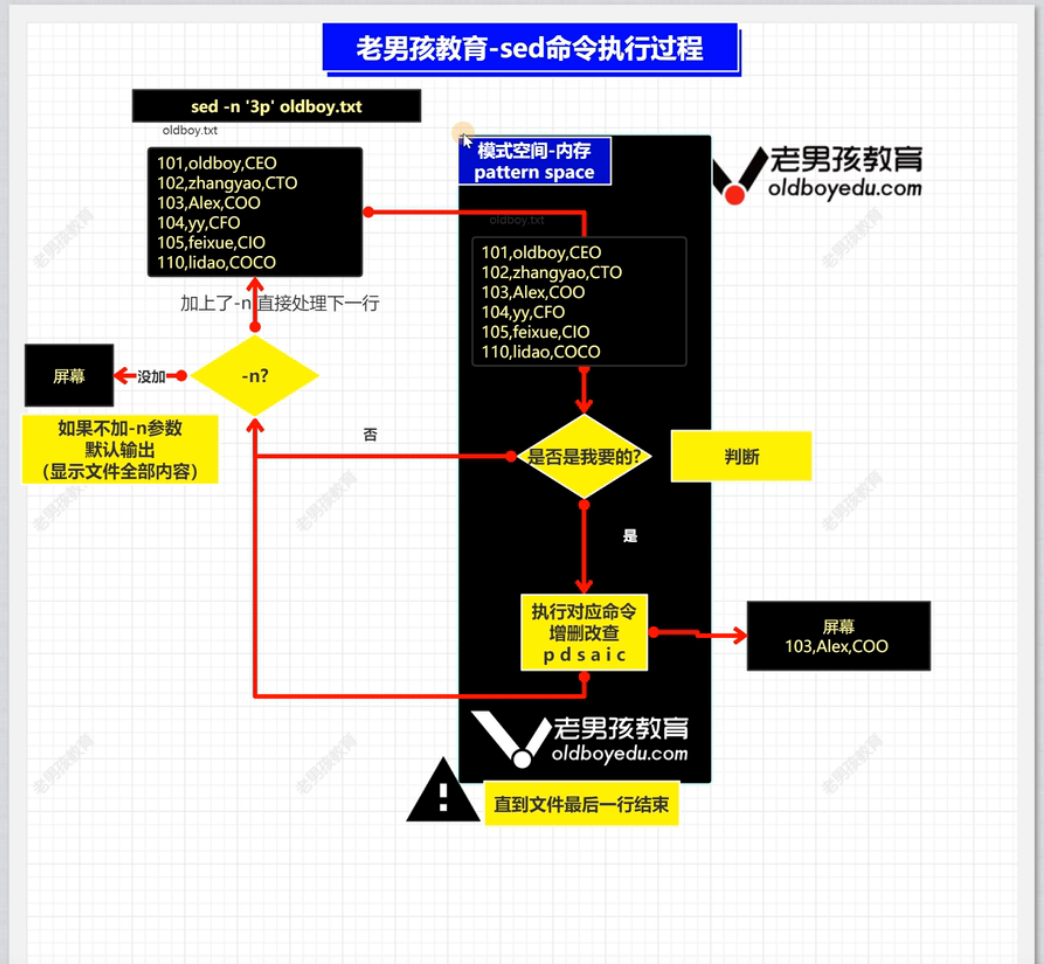
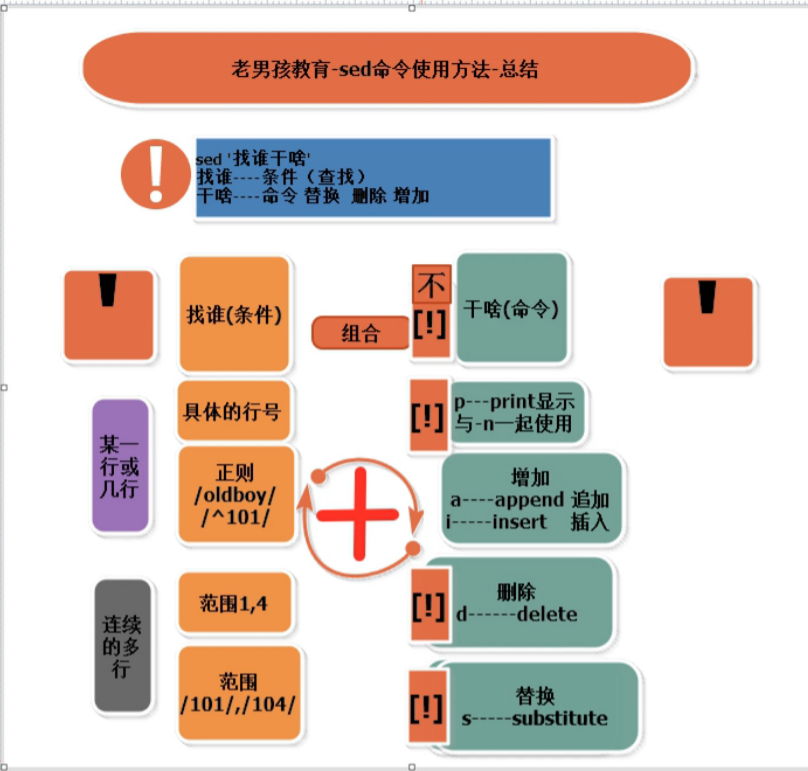
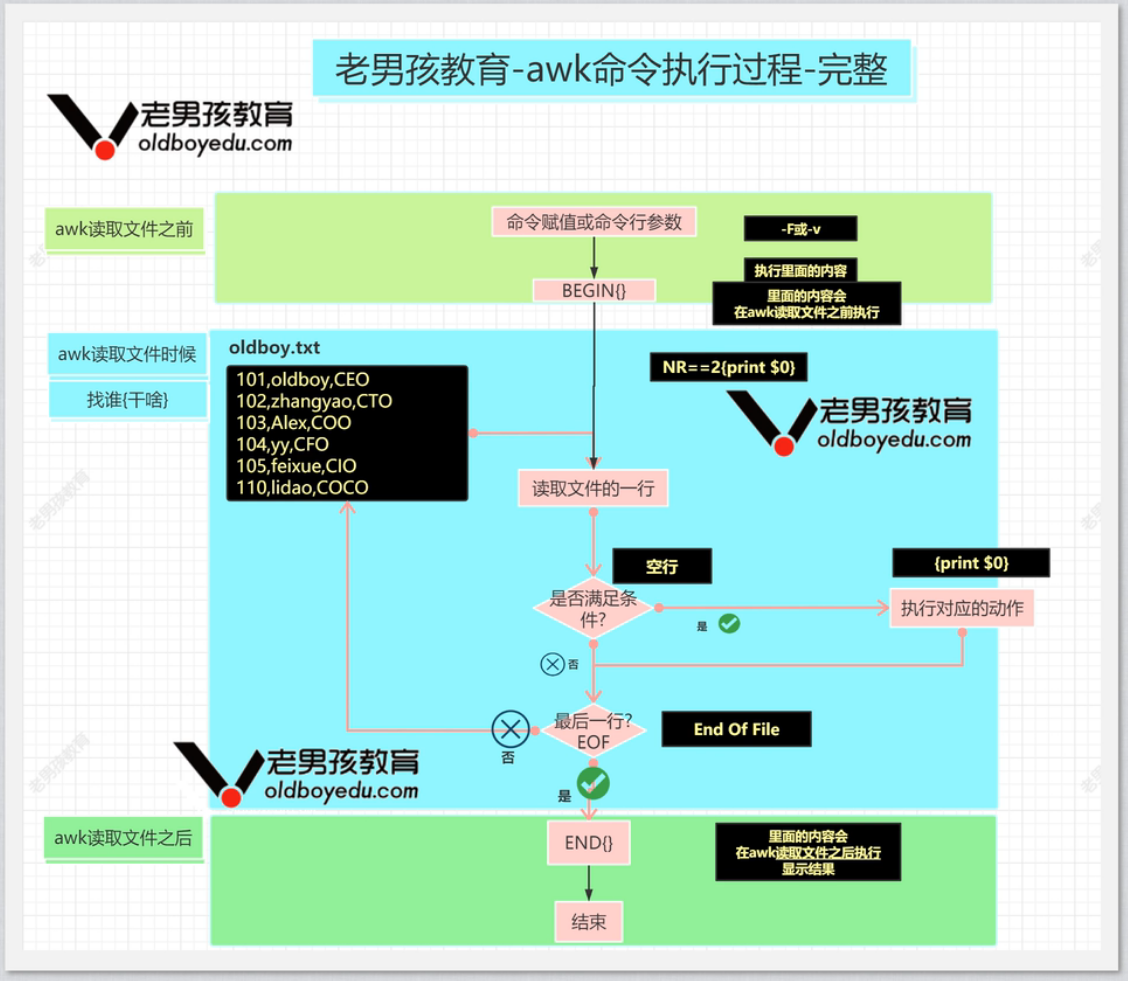
使用 //,// 来限制范围
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
wanqq@DESKTOP-QL4SAK6:/mnt/d/study/nginx/logs/parsing-record$ head -10 access.log 172.17.0.1 - - [06/Jan/2022:02:11:57 +0000] "GET / HTTP/1.1" 500 5 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" 172.17.0.1 - - [06/Jan/2022:02:11:58 +0000] "GET / HTTP/1.1" 500 5 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" 172.17.0.1 - - [06/Jan/2022:02:13:05 +0000] "GET / HTTP/1.1" 500 5 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" 172.17.0.1 - - [06/Jan/2022:02:13:06 +0000] "GET / HTTP/1.1" 500 5 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" 172.17.0.1 - - [06/Jan/2022:02:16:14 +0000] "GET / HTTP/1.1" 200 27 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" 172.17.0.1 - - [06/Jan/2022:02:16:14 +0000] "GET /favicon.ico HTTP/1.1" 200 1150 "http://localhost:8004/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" 172.17.0.1 - - [06/Jan/2022:02:17:38 +0000] "GET /pushParsingXMLTask HTTP/1.1" 404 6858 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" 172.17.0.1 - - [06/Jan/2022:02:18:10 +0000] "GET /pushParsingXMLTask HTTP/1.1" 404 6858 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" 172.17.0.1 - - [06/Jan/2022:02:18:18 +0000] "GET /pushParsingXMLTask HTTP/1.1" 404 62810 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" 172.17.0.1 - - [06/Jan/2022:02:18:31 +0000] "GET /index/pushParsingXMLTask HTTP/1.1" 200 16941 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" wanqq@DESKTOP-QL4SAK6:/mnt/d/study/nginx/logs/parsing-record$ cat access.log | awk -F" +" 'BEGIN{print "状态码 IP 请求类型 请求url"} /\[06\/Jan\/2022:02:11:57 \+0000\]/,/02:13:06/ && ($9~/[^23][0-9]{2}/) {print $9,$1,$6,$7}' | sed 's#"##' | column -t 状态码 IP 请求类型 请求url 500 172.17.0.1 GET / 500 172.17.0.1 GET / 500 172.17.0.1 GET / 500 172.17.0.1 GET /